Product Recommendation for E-Commerce Business
Hi All, In this post I will walk you though a simple yet effective product recommendation strategy along with operational code that can be utilized right away. Product recommendations are being used increasingly by online companies to boost revenues and increase the return rate of the customers.
Problem Definition
Customer Engagement is the key to success for any ecommerce service. The more time the user spends on the website the more is the potential to generate revenue. There are multiple engagement strategies that are implemented successfully. One of the most popular strategies is product recommentation. In this post we will work through a simple yet effective product recommendation algorithm which recommends products based on the current popularity/activity level. The metric we will consider for measuring the activity level is cart loads. There are many more complex recommendation algorithms which I will cover in the future. But this is a great way to get started.
Data Simulation
For the purpose of this experiement we will simulate the data which will be very close to reality. Below are some of the simulation startegies and assumptions.
Products : We will generate 100 Product IDs. Assumption that the ecommerce website sells 100 products only
Observation Window : We will consider the activity data for past 31 days (Lets say 01-Mar to 31-Mar)
Monthly Average cart loads for each product : Lets assume this follows a beta distribution with parameters 2 and 5
Daily cart loads for each product : Follows a poisson distribution with mean for each product obtained from the above step
Weekly seasonality : Lets assume a 10% spike on the weekends. This is reasonable because customer get more time over the weekends to shop
Random Normal noise : This is everywhere and we cannot escape!
# Simulate 100 products
products <- 1:100
# Simualate dates
library(lubridate)
dates <- seq(as.Date("2017-03-01"), as.Date("2017-03-31"), by = "day")
set.seed(1)
#Simulate verage cart loads per day of products : Follows a beta distribution
daily_avg <- data.frame(product_id = products,
avg = 100*rbeta(length(products), 2, 5))
# Simulate Daily cart loads of products : FOllows a poisson distribution
cart_txns <- expand.grid(product_id = products, date = dates)
#Merge daily average and transactions
cart_txns <- merge(cart_txns, daily_avg, by = "product_id")
cart_txns$carts <- sapply(cart_txns$avg, function(x) rpois(1,x))
# Simulate Weekend spike
# Carts spike by below proportion on weekends
spike <- 0.1
cart_txns$carts <- ifelse(wday(cart_txns$date) == 1 | wday(cart_txns$date) == 7,
round(cart_txns$carts *(1 + spike),0), cart_txns$carts)
# Add random noise
cart_txns$carts <- cart_txns$carts +
round(rnorm(length(cart_txns$carts), 0, 1), 0)
The data is now ready. So we can dive in to it right away and explore. We will print the top few rows of the data for reference.
head(cart_txns)
## product_id date avg carts
## 1 1 2017-03-01 17.54713 23
## 2 1 2017-03-08 17.54713 14
## 3 1 2017-03-18 17.54713 23
## 4 1 2017-03-23 17.54713 12
## 5 1 2017-03-16 17.54713 15
## 6 1 2017-03-04 17.54713 21
Understanding the trend
Lets randomly select a product and look at the cart trend over the observatio period.
p <- sample(products, 1)
library(dplyr)
library(ggplot2)
cart_txns[cart_txns$product_id == p, ] %>%
ggplot(aes(x = date, y = carts)) +
geom_line(size = 1) +
labs(title = sprintf("Cart trend of product %s", p)) +
my_theme() + geom_smooth()
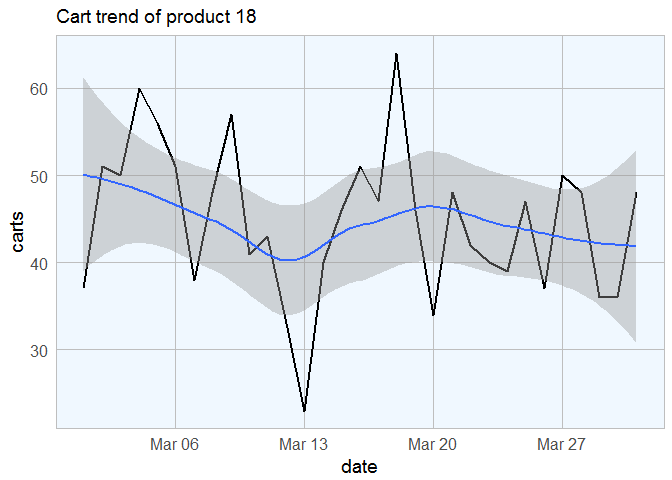
Smoothing the trend
The trend we observed above usually includes noise (although we added it in this case for the purpose of simulation). Smoothing removes the noise so that the long term trend of the line can be observered more clearly. We will write a small custom function for smoothing this signal.
Before we apply the smoothing function we will prepare the data. The algorithm for smoothing is adopted from scipy cookbook. We basically create reflected copies of the signal of length equal to window size on either side of the actual signal so that the output signal is of the same length as the original signal.
sig_smooth <- function(x, window_size = 7, window_type = "hamming.window") {
# Add reflection on either end
x <- c(rev(x[1:window_size]), x, rev(x)[1:window_size])
#Create filter weights
fil <- do.call(window_type, list(window_size))
#Apply the smoothing filter
x <- stats::filter(x, fil/sum(fil))
#Remove the unwanted ends
x[(window_size+1):(length(x) - 2*window_size)]
}
Now we have the smoothing function ready. Lets see how the smoothed version looks compared to the original.
# Create a combined data frame
cart_txns <- cart_txns %>% arrange(product_id, date)
library(data.table)
cart_txns <- as.data.table(cart_txns)
cart_txns[, smooth := as.numeric(sig_smooth(carts)), by = product_id]
## product_id date avg carts smooth
## 1: 1 2017-03-01 17.54713 23 19.38253
## 2: 1 2017-03-02 17.54713 16 17.88855
## 3: 1 2017-03-03 17.54713 12 17.22590
## 4: 1 2017-03-04 17.54713 21 18.02410
## 5: 1 2017-03-05 17.54713 19 18.98494
## ---
## 3096: 100 2017-03-27 20.13960 27 20.57831
## 3097: 100 2017-03-28 20.13960 27 18.70181
## 3098: 100 2017-03-29 20.13960 19 17.07530
## 3099: 100 2017-03-30 20.13960 14 16.52108
## 3100: 100 2017-03-31 20.13960 25 16.65663
cart_txns[cart_txns$product_id == p, ] %>%
ggplot(aes(x = date)) +
geom_line(aes(y = carts, col = "carts"), size = 1) +
labs(title = sprintf("Cart and smooth trend of product %s", p)) +
my_theme() +
geom_line(aes(y = smooth, col = "smooth"), size = 1)
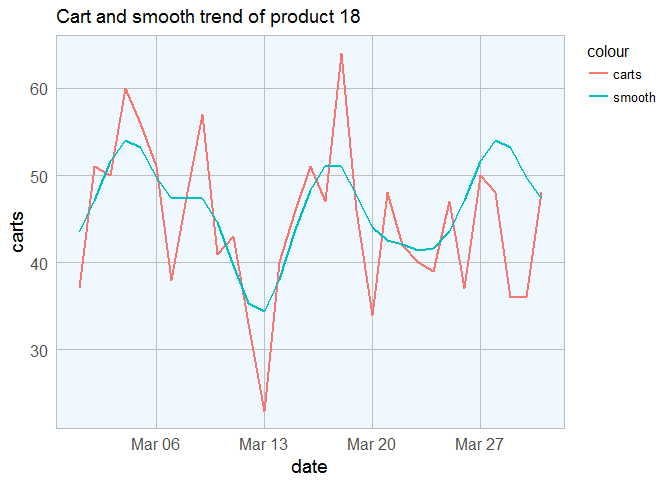
The smoothing function did a pretty good job at flattening the daily
noise. Finally, we will normalize the carts and smooth variables.
This will help to compare the trends of various products with vastly
unequal means. For this purpose we will use min-max normalization.
Min-max normalization subtracts the mean/median from every element and
divides the result by the difference between the minimum and the
maximum.
invisible(cart_txns[, ":=" (
carts_norm = as.numeric(
(carts - median(carts))/(max(carts) - min(carts))
),
smooth_norm = as.numeric(
(smooth - median(smooth))/(max(smooth) - min(smooth)))
),
by = product_id])
cart_txns[cart_txns$product_id == p, ] %>%
ggplot(aes(x = date)) +
geom_line(aes(y = carts_norm, col = "carts_norm"), size = 1) +
labs(title = sprintf("Normalized Cart and smooth trend of product %s", p)) +
my_theme() +
geom_line(aes(y = smooth_norm, col = "smooth_norm"), size = 1)
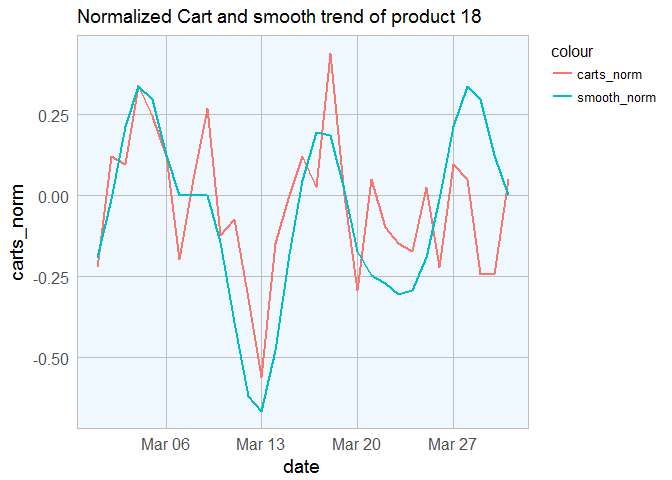
In the graph above, observe the change in the y axis scale. We basically centered the values at 0 and scaled them to be between -1 and 1.
Lets move on to the next step.
Trend Identification
Identifying trend is very simple. Mathematically speaking, trend is nothing but the slope of ascend or descend. So we will take the difference between current value and the previous value to ascertain the trend. The below code chunk will do exactly the same and plot it against the smoothed and normalized carts.
invisible(
cart_txns[,
smooth_norm_prev := shift(smooth_norm, type = "lag"),
by = product_id]
)
# Then compute the trend by taking the difference
invisible(
cart_txns[,
trend := as.numeric(smooth_norm - smooth_norm_prev),
by = product_id]
)
# Plotting the Trend
cart_txns[cart_txns$product_id == p, ] %>%
ggplot(aes(x = date)) +
geom_line(aes(y = carts_norm, col = "carts_norm"), size = 1) +
labs(title = sprintf("Normalized Cart, smooth and trend of product %s", p)) +
my_theme() +
geom_line(aes(y = smooth_norm, col = "smooth_norm"), size = 1) +
geom_line(aes(y = trend, col = "trend"), size = 1)
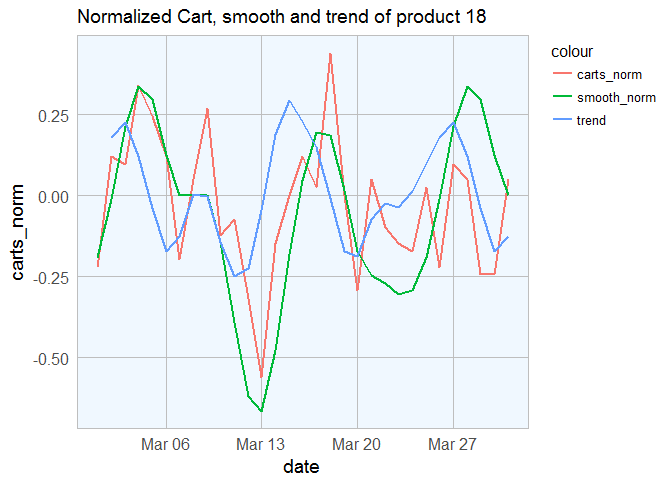
Instead of looking only at the trend value on the current day, we can
aswell take a weighted average of trend over past n days to factor in
for trend of trends. This will give us a more robust representation of
trend. For simplicity we will consider n = 1 and weights as
c(1, 0.5).
invisible(
cart_txns[,
trend_robust := as.numeric(trend + 0.5*shift(trend, type = "lag")),
by = product_id]
)
# Plotting trend_robust
cart_txns[cart_txns$product_id == p, ] %>%
ggplot(aes(x = date)) +
#geom_line(aes(y = carts_norm, col = "carts_norm"), size = 1) +
labs(title = sprintf("Smoothed and robust trend of product %s", p)) +
my_theme() +
geom_line(aes(y = smooth_norm, col = "smooth_norm"), size = 1) +
#geom_line(aes(y = trend, col = "trend"), size = 1) +
geom_line(aes(y = trend_robust, col = "trend_robust"), size = 1)
# Now we will select the trend_robust for every product on the day of interest, 31-Mar in this case
latest_trend <- cart_txns[date == "2017-03-31",
c("product_id", "trend_robust")][order(trend_robust, decreasing = TRUE)]
Now lets print the top 6 trending products
print("Top Recommended Products")
## [1] "Top Recommended Products"
result <- apply(head(latest_trend),
MARGIN = 1,
function(x) cat("Product ",
x[1],
" (Trend Score ", x[2], ")",
sep = "",
fill = TRUE))
## Product 53 (Trend Score 0.3213265)
## Product 7 (Trend Score 0.286206)
## Product 32 (Trend Score 0.2800515)
## Product 57 (Trend Score 0.222346)
## Product 62 (Trend Score 0.2099849)
## Product 5 (Trend Score 0.2077364)
That’s it! These are the top 6 recommended products which are currently trending. These products can now be displayed on the website in real time if we take the unit of measurement to hour or event minutes instead of days.
Acknowledgements: 1. A Simple Trending Products Recommendation Engine in Python