Churn Prediction for Preemptive Marketing
Hello All, In this post I will demonstrate a very practical approach to developing a churn prediction model with the data available in the organizations. The approach can be easily replicated if you are using SQL Server 2016 with R Services.
Overview
Customer churn is typically defined as the attrition of the customer base to competition. Any organization willing to expand its customer base needs to have its churn rate lower than the acquisition rate. It has been proven numerous times through various research studies that acquiring news customers is about 5 to 25 times more expensive than retaining the existing ones. Therefore it makes very much sense to build strategies and execute them with precision to contain the churn rate.
But there is a step zero to this process and in my opinion it is the single most important step. For the strategy to produce intended results we need to target the right audience. Organizations need to identify those set of customers who are most likely to churn in the short to mid term. Once the segment is identified, the characteristics can be studied to design suitable strategies. These set of potential churner can be identified with a fair amount of confidence level using the intelligence hidden in the data. Imagine the competitive advantage organizations can achieve by preemptively targeting these customers and change its own destiny!
In this post I will walk through one such methodology which can be easily replicated with what ever data is available. Remember, the more information we have about the customers the better we are at accomplishing this task.
Objective
If you work with SQL Server 2016 with installed R services, at the end of this post you will be able to successfully build a customer churn model and score the new unseen data in the production environment. You can then use the scored data by any other application like a management dashboard or a campaign management system or call centre application to reach out to those set of customers who are most likely to churn.
Data Source and Previous Work
This experiement is motivated after reading an eBook published on Microsoft Virtual Academy. With due credit to the creators, I will be using the data from this experiment.
There are basically 2 tables in the SQL server that I will be using for this experiment.
-
The training data which contains multiple attributes for each of the customers
-
The testing data which will be used to evaluate the models. We will choose the model which performs the best on this unseen test data
We will be using the training data to build a machine learning model. In other words the model will identify the underlying patterns in the data and help us to predict the potential churners in the testing data.
About the Environment
The primary client of this experiment is RStudio, but I will be using the data residing in the SQL Server 2016 instance. I will be exptensively using the RevoScaleR package to create and manipulate the SQL server data as required. Further, all the model building and scoring will be done on the SQL server. This will allow us to take advantage of the powerful hardware of the SQL Server rather than using the resources of the local machine. So we will create 2 compute contexts and switch between them as necessary.
```r
# Define the connection string to connect to the SQL Server. Replace ??? with your info
connection_string <- "Driver=SQL Server;
Server=??? ;
Database= ??? ;
UID= ?? ;
PWD = ???"
# Define SQL Server compute context parameters
sqlShareDir <- paste("C:", Sys.getenv("USERNAME"), sep = "")
dir.create(sqlShareDir, recursive = TRUE)
sqlWait <- TRUE
sqlConsoleOutput <- FALSE
sql <- RxInSqlServer(
connectionString = connection_string,
shareDir = sqlShareDir,
wait = sqlWait,
consoleOutput = sqlConsoleOutput)
# Define Local compute context
local <- RxLocalSeq()
# Set the Compute Context to Local
rxSetComputeContext(local)
```
Exploring the training data
The training data is basically a collection of variables which represents
the current state of the customer. This data or information may lie
scattered with multiple teams in the organization and it requires a
concerted effort to bring it all together. The data we have at hand is
stored in the table called edw_cdr_train_SMOTE which is a clean
structured dataset. We need to create a data scource object to be able
to access the training data.
edw_cdr_train_smote <- RxSqlServerData(table = "edw_cdr_train_SMOTE",
connectionString = connection_string,
stringsAsFactors = TRUE)
It contains the following information or variables.
| varType | |
|---|---|
| age | numeric |
| annualincome | numeric |
| calldroprate | numeric |
| callfailurerate | numeric |
| callingnum | numeric |
| customerid | numeric |
| customersuspended | factor |
| education | factor |
| gender | factor |
| homeowner | factor |
| maritalstatus | factor |
| monthlybilledamount | numeric |
| noadditionallines | factor |
| numberofcomplaints | numeric |
| numberofmonthunpaid | numeric |
| numdayscontractequipmentplanexpiring | numeric |
| occupation | factor |
| penaltytoswitch | numeric |
| state | factor |
| totalminsusedinlastmonth | numeric |
| unpaidbalance | numeric |
| usesinternetservice | factor |
| usesvoiceservice | factor |
| percentagecalloutsidenetwork | numeric |
| totalcallduration | numeric |
| avgcallduration | numeric |
| churn | factor |
There are a total of 27 variables which are pretty much self explanatory. Please note that getting data to this shape is in itself a humongous task and we appreciate the work done on this so far. As you can observe, this data is from a telecommunications company. There is huge scope for futher feature engineering which we will skip in this post. But as data science is an iterative process, we can revisit feature engineering to improve the performance of our model.
Building Models
Lets jump on to building 3 different machine learning models. Before
that lets create a formula object that we pass on to our models. We want
to model churn as a function of all other variables.
train_vars <- rxGetVarNames(edw_cdr_train_smote)
train_vars <- train_vars[!train_vars %in% c("churn")]
temp<-paste(c("churn",paste(train_vars, collapse="+") ),collapse="~")
formula<-as.formula(temp)
Model 1 : Simple Logistic Regression
Our first model will be a simple logistic regression. We will build this model in the SQL Server.
# Create SQL Server Data Source
edw_cdr_train_smote <- RxSqlServerData(table = "edw_cdr_train_SMOTE",
connectionString = connection_string,
stringsAsFactors = TRUE)
# Change compute context
rxSetComputeContext(sql)
# Logistic Regression Model
logit_model <- rxLogit(formula = formula,
data = edw_cdr_train_smote
)
Model 2: Gradient Boosted Decision Tree
Our second model will be a Gradient Boosted Decision Tree. The parameters have been adjusted to give a better performance. We can further fine tune the parameters.
btree_model <- rxBTrees(formula = formula,
data = edw_cdr_train_smote,
learningRate = 0.1,
minSplit = 10,
minBucket = 1,
mTry = 5,
maxDepth = 16,
replace = TRUE,
importance = TRUE,
cp = 0,
nTree = 10,
seed = 123,
parms=list(loss=c(0,8,1,0)),
lossFunction = "multinomial")
Model 3: Random Forest
The last model will be the Random Forest. Again the parameters have been adjusted for better model performance
# Random Forest Model
forest_model <- rxDForest(formula = formula,
data = edw_cdr_train_smote,
nTree= 100,
mTry = 2,
maxDepth = 32,
minSplit = 10,
minBucket = 1,
replace = TRUE,
importance = TRUE,
parms=list(loss=c(0,4,1,0)),
seed = 123)
Scoring Models
The testing data is in the table edw_cdr_new. But there is some
duplicate information, so we will leave the duplicates based on a
certain business logic. Note here that we can seamlessly use the R IDE and RevoScaleR package to deploy complex queries to the SQL server to create data sources on the fly.
# Set back the compute context to local
rxSetComputeContext(local)
# Creating the Data Source for Test Data by removing the duplicates
test <- RxSqlServerData(sqlQuery = "
SELECT *
FROM (
SELECT *,
RANK() OVER(PARTITION BY customerid ORDER BY churn DESC,
totalcallduration DESC) AS rnk
FROM edw_cdr_new) AS t
WHERE t.rnk = 1",
connectionString = connection_string)
Now we will score our models on the unseen test data and store the scored values in a new SQL table for each of the models.
# Change compute context as we want scoring in SQL server
rxSetComputeContext(sql)
# Point to the table where we will store the predictions
# Logistic Regression
logitpreds <- RxSqlServerData(table = "LPreds_table",
connectionString = connection_string)
# Boosted Tree
tpreds <- RxSqlServerData(table = "TPreds_table",
connectionString = connection_string)
# Random Forest
fpreds <- RxSqlServerData(table = "FPreds_table",
connectionString = connection_string)
# Scoring using Logit Model
rxPredict(modelObject = logit_model,
data = test,
outData = logitpreds,
type = "response",
extraVarsToWrite = c("customerid", "churn"),
predVarNames = c("P1"))
# We have to additionally create 2 new variables for Logit Model to be consistant
# with other models
rxExecuteSQLDDL(outOdbcDS,
sSQLString = "ALTER TABLE LPreds_table ADD P0 AS (1-P1)")
rxExecuteSQLDDL(outOdbcDS,
sSQLString = "ALTER TABLE LPreds_table
ADD prediction AS CASE WHEN P1>0.5 THEN 1 ELSE 0 END")
# Scoring using BT Model
rxPredict(modelObject = btree_model,
data = test,
outData = tpreds, type = "prob",
extraVarsToWrite = c("customerid", "churn"),
predVarNames = c("P0", "P1", "prediction"))
# Scoring using RF Model
rxPredict(modelObject = forest_model,
data = test,
outData = fpreds, type = "prob",
extraVarsToWrite = c("customerid", "churn"),
predVarNames = c("P0", "P1", "prediction"))
We have successfully built the models and stored the scored values in the SQL Server. Now its time to select the best model.
Model Evaluation
To choose the best performing model we need to evaluate based on a common metric. For this activity we will compare the accuracy, precision, recall, f1 score and AUC of the ROC curve for all these 3 models. Ultimately we will choose the best model based on the AUC. I will write a helper function to extract these metric from the scored data.
evaluate_model <- function(data) {
sum <- rxCrossTabs(~ churn : prediction, data)
confusion <- sum$counts[[1]]
print(confusion)
tp <- confusion[2, 2]
fn <- confusion[2, 1]
fp <- confusion[1, 2]
tn <- confusion[1, 1]
accuracy <- (tp + tn) / (tp + fn + fp + tn)
precision <- tp / (tp + fp)
recall <- tp / (tp + fn)
fscore <- 2 * (precision * recall) / (precision + recall)
metrics <- c("Accuracy" = accuracy, "Precision" = precision,
"Recall" = recall, "F-Score" = fscore)
return(metrics)
}
We will pass the scored values stored in the SQL tables to our helper function to see the results.
evaluate_model(logitpreds)
## prediction
## churn 0 1
## 0 4122 438
## 1 348 83
## Accuracy Precision Recall F-Score
## 0.8425165 0.1593090 0.1925754 0.1743697
evaluate_model(tpreds)
## prediction
## churn 0 1
## 0 4526 34
## 1 391 40
## Accuracy Precision Recall F-Score
## 0.91484672 0.54054054 0.09280742 0.15841584
evaluate_model(fpreds)
## prediction
## churn 0 1
## 0 4538 22
## 1 406 25
## Accuracy Precision Recall F-Score
## 0.91424564 0.53191489 0.05800464 0.10460251
We can see the confusion matrix and other metrics for each of the
models. Clearly Random Forest Models, seems to be the winner. Lastly
lets also visually compare the ROC curve for these models. For the ROC
curves we need to import and merge the scored probabilities in the local
R IDE. We can do that either by join or merge functions in R. I stored the merged data in the data frame called allpreds
Then we can use the rxRocCurve to compare the AUC and ROC curves.
rxRocCurve(actualVarName = "churn",
predVarNames = c("RF", "BT", "LR"),
data = allpreds,
legend = TRUE)
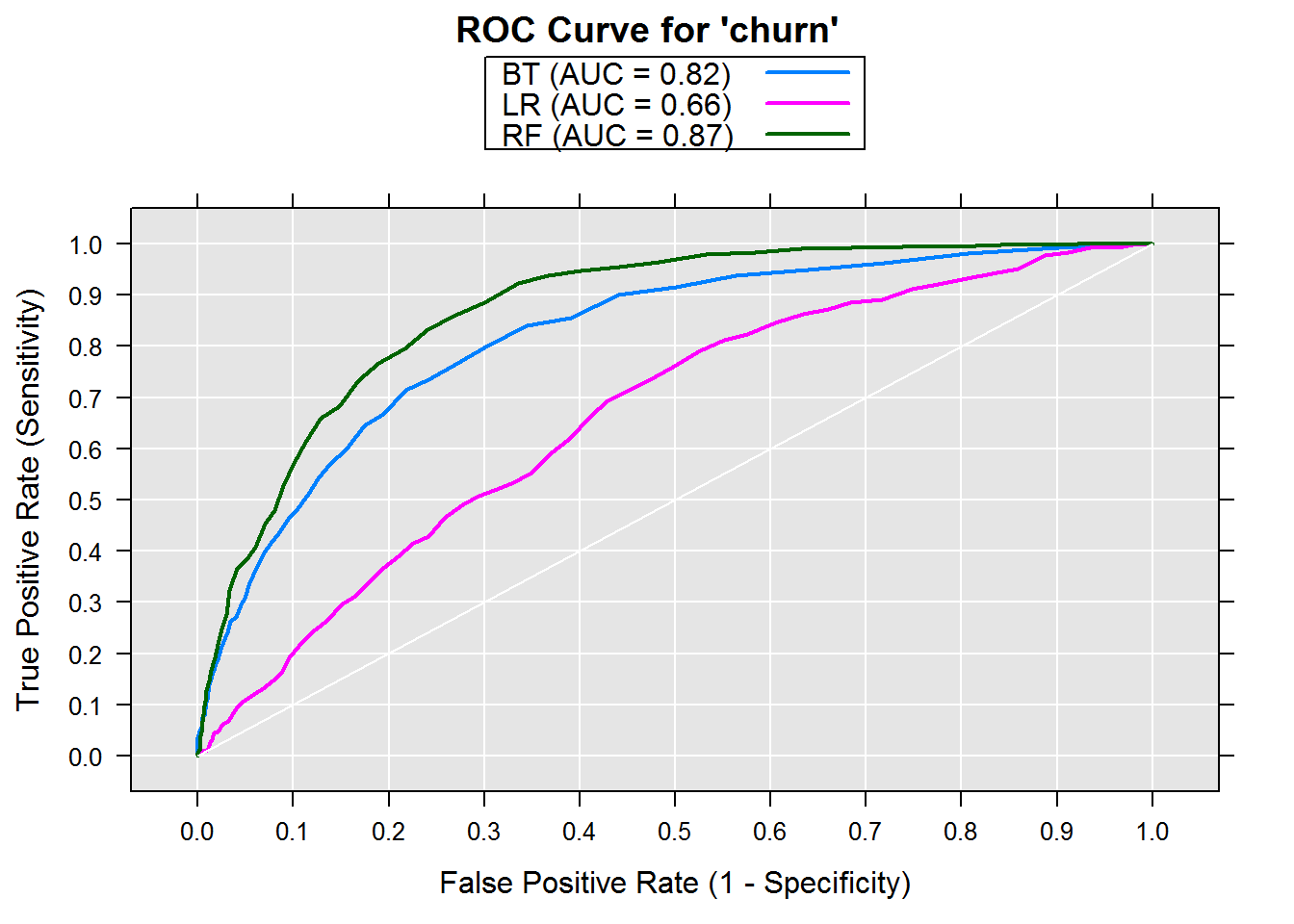
The Random Forest model has the highest area under the curve of 0.87, when compared to Boosted Trees and simple Logisitic Regression.
Next Steps
We will choose Random Forest as our best model. The next step is operationalizing this model in to the production environment. SQL Server 2016 with R Services makes it extremely easy to operationalize our trained models. Firstly, we need to save our first model as a table in the SQL server using the below code.
# Save the model locally
saveRDS(forest_model, file = "forest_model.rds")
## Read Binary data from the .rds file
forest_model_raw <- readBin("forest_model.rds",
"raw",
n = file.size("forest_model.rds"))
forest_model_char <- as.character(forest_model_raw)
# Point to a table in the SQL Server where we want to savae the model.
forest_model_sql <- RxSqlServerData(table = "forest_model_sql",
connectionString = connection_string)
# Write to the table
rxDataStep(inData = data.frame(model = forest_model_char),
outFile = forest_model_sql,
overwrite = TRUE)
We can then write a stored procedure with embedded R code and invoke the stored procedure whenever we want to score the unseen data. Lets say we have a new streaming data in the table new_stream_data and our model stored in forest_model_sql, we can use the below store procedure to score the unseen data and save the predictions to the table new_stream_pred.
ALTER procedure [dbo].[predict_customer_churn]
as
begin
declare @rx_model varbinary(max) = (select model from forest_model_sql);
-- Use the selected model for prediction
exec sp_execute_external_script
@language = N'R'
, @script = N'
require("RevoScaleR");
predictions <- rxPredict(modelObject = rx_model,
data = new_stream_data,
type="prob",
overwrite = TRUE)
print(head(predictions))
threshold <- 0.5
predictions$X0_prob <- NULL
predictions$churn_Pred <- NULL
names(predictions) <- c("probability")
predictions$prediction <- ifelse(predictions$probability > threshold, 1, 0)
predictions$prediction<- factor(predictions$prediction, levels = c(1, 0))
new_stream_pred <- cbind(new_stream_pred[,c("customerid")],predictions)
new_stream_pred <-as.data.frame(new_stream_pred);
'
, @input_data_1 = N'select * from new_stream_data'
, @input_data_1_name = N'new_stream_data'
, @output_data_1_name=N'new_stream_pred'
, @params = N'@rx_model varbinary(max)'
, @rx_model = @rx_model
with result sets (("customerid" int, "probability " float, "prediction" float));
end;
Finally, we can set a trigger to invoke the stored procedure whenever we have new data in the table. These predictions can now be used downstream by either applications or teams to take actions on time.
The main purpose of this post was to demonstrate how we can use R and SQL Server R Services coherently to quickly build, evaluate and productionalize smart solutions. This can help organizations to make use of intelligence in the data to take better informed decisions. I hope you enjoyed this post and do leave a comment to discuss!